自定义字体是一种很常见的反爬虫方法,本文将以晋江文学城为例详解如何对抗自定义字体反爬。
随便打开一章晋江VIP章节,查看源码,发现一部分在网页中正常显示的字符,在网页源码却中显示为了方块。
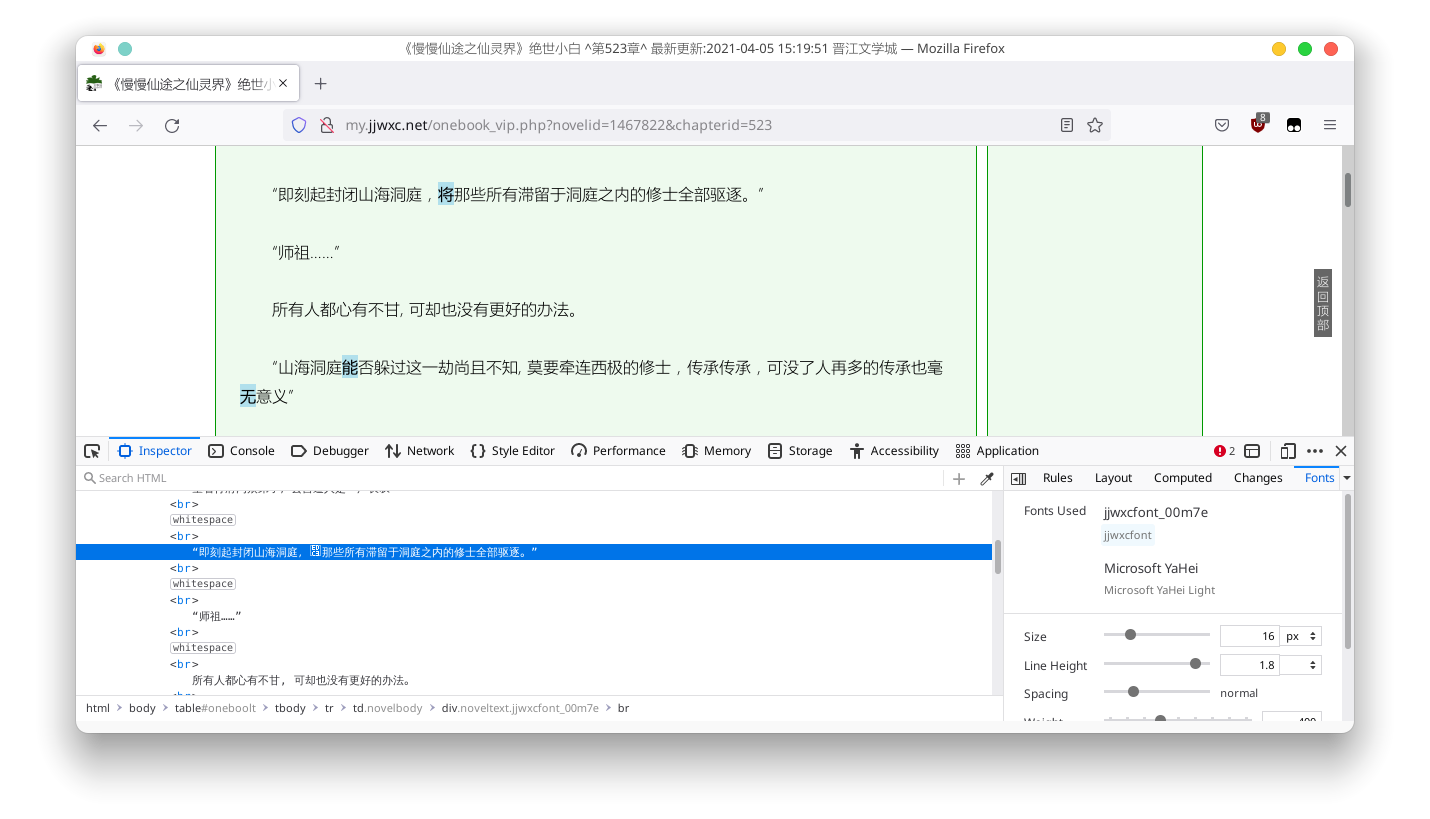
通过 Fonts 选项卡,可以发现这些方块字体使用了自定义字体(jjwxcfont)。
如果想要制作一个晋江小说下载器,那么这些使用了自定义字体的方块字是一道绕不开的障碍。
除了先全文截图再直接全图OCR,这种简章粗暴的方法之外。
另一种通用的方法是,先获取并生成自定义字体的字符映射表,然后根据字符映射表将自定义字体字符映射回通用字符。
下图即是某一晋江字体的字符映射表。

本文将重点讲解如何快速高效自动化地生成晋江自定义字体字符映射表。
大致印象¶
mkdir fonts
wget http://static.jjwxc.net/tmp/fonts/jjwxcfont_0004v.woff2?h=my.jjwxc.net -O fonts/jjwxcfont_0004v.woff2
wget http://static.jjwxc.net/tmp/fonts/jjwxcfont_00rmg.woff2?h=my.jjwxc.net -O fonts/jjwxcfont_00rmg.woff2
使用上述命令下载 jjwxcfont_0004v.woff2 字体文件,之后本文将以该字体为例进行讲解。
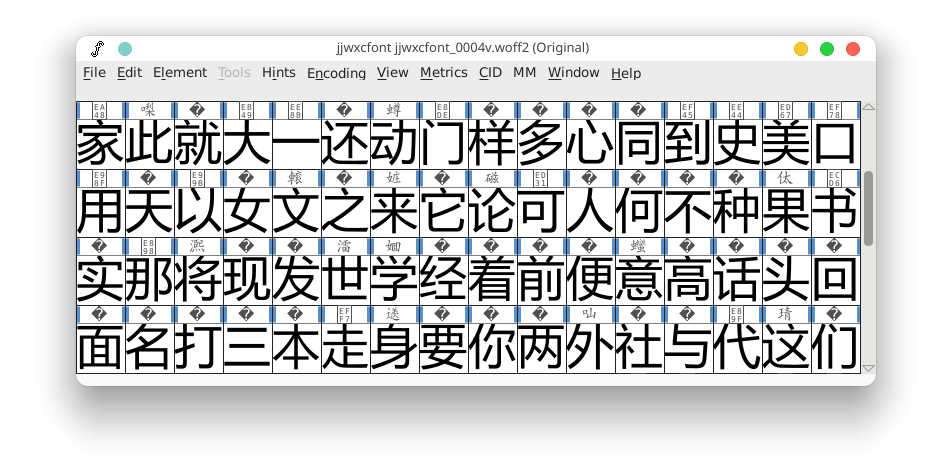
使用 fontforge 打开该字体文件。
选择选项:Encoding > Reencode > Glyph Order
查看该字体文件,获得一个该字体文件的大致印象。
OCR法¶
OCR法即获取字体文件下所有字符,并将其转换为图片,通过OCR软件识别后进行标记,最终生成字符映射表。
import os
import shutil
import tempfile
from fontTools.ttLib import woff2, ttFont
PWD = os.getcwd()
TMP: str = tempfile.mkdtemp()
FontsDir: str = os.path.join(PWD, 'fonts')
def clear() -> None:
"""
清除临时文件
"""
shutil.rmtree(TMP)
def listTTF(ttf: ttFont.TTFont) -> list[str]:
"""
输入字体文件,输出该字体文件下所有字符。
"""
return list(set(map(lambda x: chr(x), ttf.getBestCmap().keys())))
载入并解析字体
fontname: str = 'jjwxcfont_0004v'
fontpath: str = os.path.join(FontsDir, f'{fontname}.woff2')
ttfpath: str = os.path.join(TMP,f'{fontname}.ttf')
woff2.decompress(fontpath, ttfpath)
ttf = ttFont.TTFont(ttfpath)
chars = listTTF(ttf)
共有201个字符
print(len(chars))
print(chars)
将自定义字体的字符列表生成为每行20个字的文本,用于后续识别工作。
import itertools
_chars = filter(lambda x: x != 'x', chars)
_ = iter(_chars)
chars_split: list[list[str]] = [list(itertools.islice(_, 20)) for i in range(10)]
ocr_txt: str = '\n'.join([''.join(cs) for cs in chars_split])
del _
del _chars
print(ocr_txt)
调用 imagemagick 所附带的 convert 命令,将之前准备好的自定义字符文本绘制为图片。
import subprocess
txt_path: str = os.path.join(TMP, 'ocr.txt')
img_path: str = os.path.join(TMP, 'ocr.png')
with open(txt_path, 'w') as f:
f.write(ocr_txt)
subprocess.call(["convert", "-font", ttfpath, "-pointsize", "64", "-background", "rgba(255,255,255)",
f"label:@{txt_path}", img_path])
结果如下:
from PIL import Image, ImageDraw, ImageFont
from IPython.display import display
ocr_img = Image.open(img_path)
display(ocr_img)

调用 tesseract 识别该图片。
tesseract_result_name: str = os.path.join(TMP, 'tesseract_result.txt')
subprocess.call(["tesseract", img_path, tesseract_result_name, "-l", "chi_sim", "--psm", "6"])
tesseract 识别结果如下:
with open(f'{tesseract_result_name}.txt', 'r') as f:
tesseract_result = f.read()
print(tesseract_result)
识别结果相当不错。
接下来就是生成字符映射表了。
table = dict(zip(
filter(lambda x: x != '\n', list(ocr_txt)),
filter(lambda x: 19967 < ord(x) < 40870, list(tesseract_result))
))
print(table)
OCR法(无外部依赖版)¶
上述方法除了python之外,还需要额外安装 imagemagick、tesseract以及tesseract中文训练数据,这三个部件加起来大概快有100MB。
好像有一点臃肿,那么能不能精简一点呢?
让我们再看一看晋江的自定义字体。
我们很容易发现:晋江自定义字体与方正兰亭黑(微软雅黑)极其相似。
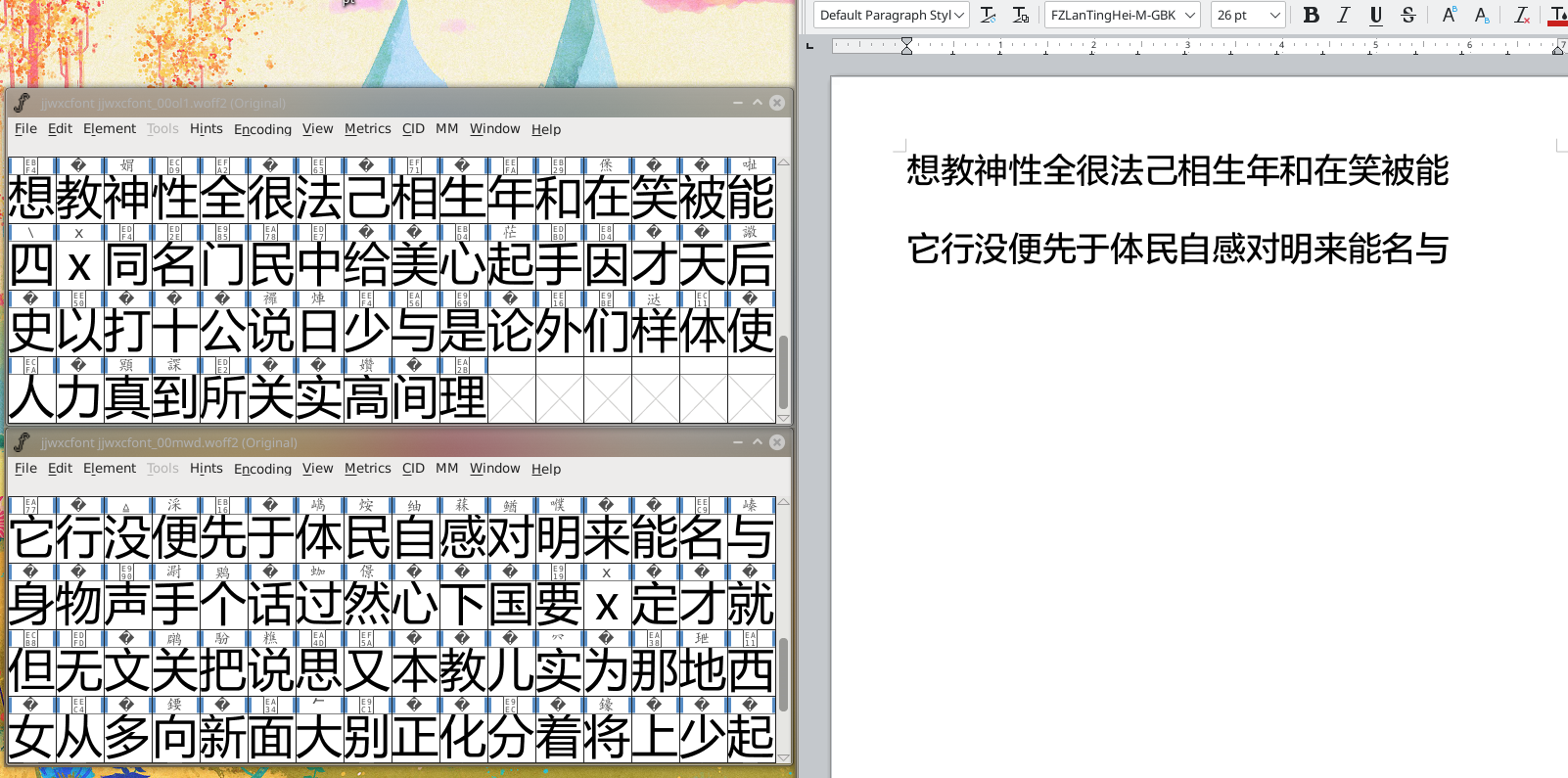
因此可以基于这点构建一个轻量级的识别程序。
大致流程:
- 绘制微软雅黑所有字符
- 绘制晋江自定义字体所有字符
- 使用已知的前者对未知的后者进行匹配,根据差异度找出最有可能的字符。
载入双方字体
SIZE: int = 228
FZfont: ImageFont.FreeTypeFont = None
try:
# Windows平台直接调用系统字体即可
FZfont = ImageFont.truetype(font='Microsoft YaHei', size=SIZE)
except Exception:
# 其他平台需手动将字体文件放入 fonts 目录
FZfont = ImageFont.truetype(font=os.path.join(FontsDir, 'FZLanTingHei-M-GBK.ttf'), size=SIZE)
JJfont: ImageFont.FreeTypeFont = ImageFont.truetype(font=os.path.join(ttfpath), size=SIZE-5)
建构基本函数
W, H = (SIZE, SIZE)
def draw(character: str, fontTTF: ImageFont.FreeTypeFont) -> ImageDraw:
"""
输入字符以及字体文件,输出绘制结果。
"""
image = Image.new("RGB", (W, H), "white")
d = ImageDraw.Draw(image)
offset_w, offset_h = fontTTF.getoffset(character)
w, h = d.textsize(character, font=fontTTF)
pos = ((W - w - offset_w) / 2, (H - h - offset_h) / 2)
d.text(pos, character, "black", font=fontTTF)
return image
def drawFZ(character: str) -> ImageDraw:
"""
输入字符,输出方正兰亭黑字体绘制结果。
"""
return draw(character, FZfont)
def drawJJ(character: str) -> ImageDraw:
"""
输入字符,输出晋江自定义字体绘制结果。
"""
return draw(character, JJfont)
import numpy as np
def compare(image1: ImageDraw, image2: ImageDraw) -> float:
"""
输入两字体图像,输出差异度。
"""
array1 = np.asarray(image1.convert('1'))
array2 = np.asarray(image2.convert('1'))
diff_array: np.ndarray = array1 ^ array2
diff = np.count_nonzero(diff_array) / np.multiply(*diff_array.shape)
return diff
绘制方正字体所有字符,本步骤需花费大量时间以及大量内存。
FZttf = ttFont.TTFont(os.path.join(FontsDir, 'FZLanTingHei-M-GBK.ttf'))
FZkeys = list(filter(lambda x: 19967 < ord(x) < 40870, listTTF(FZttf)))
FZimgs = map(lambda x: drawFZ(x), FZkeys)
FZtable = dict(zip(FZkeys, FZimgs))
del FZkeys
del FZimgs
绘制晋江字体
JJkeys = list(filter(lambda x: x != 'x', chars))
JJimgs = list(map(lambda x: drawJJ(x), JJkeys))
JJtable = dict(zip(JJkeys, JJimgs))
比较两字体
def match(jjimg: ImageDraw) -> tuple[str, float]:
"""
将晋江字符绘制结果与方正字体进行匹配
"""
m:str = None
d:float = None
for fzkey in FZtable:
fzimg = FZtable[fzkey]
diff = compare(jjimg, fzimg)
if d is None:
m = fzkey
d = diff
else:
if diff < d:
m = fzkey
d = diff
return m, d
i = 1
jjkey = JJkeys[i]
jjimg = JJimgs[i]
jjmatch = match(jjimg)
jjmatch
jjkey
jjimg

可以看出识别成功。
如需识别所有晋江字符,for i in range(len(JJkeys)) 跑一个循环即可。
比较一下方正字体以及晋江字体
from PIL import ImageChops
i0 = drawJJ(jjkey)
i1 = drawFZ(jjmatch[0])
img_diff = ImageChops.difference(i0, i1)
display(img_diff)
del i0, i1, img_diff

当然每次这样跑,速度有一些慢。
因此可以先使用 imagehash 先筛选一下,只对 imagehash 相近的字符进行精细比较。这样可以节省大量时间。
具体代码就不在这里列了,详细代码可以参见此处。
直接比较字体法¶
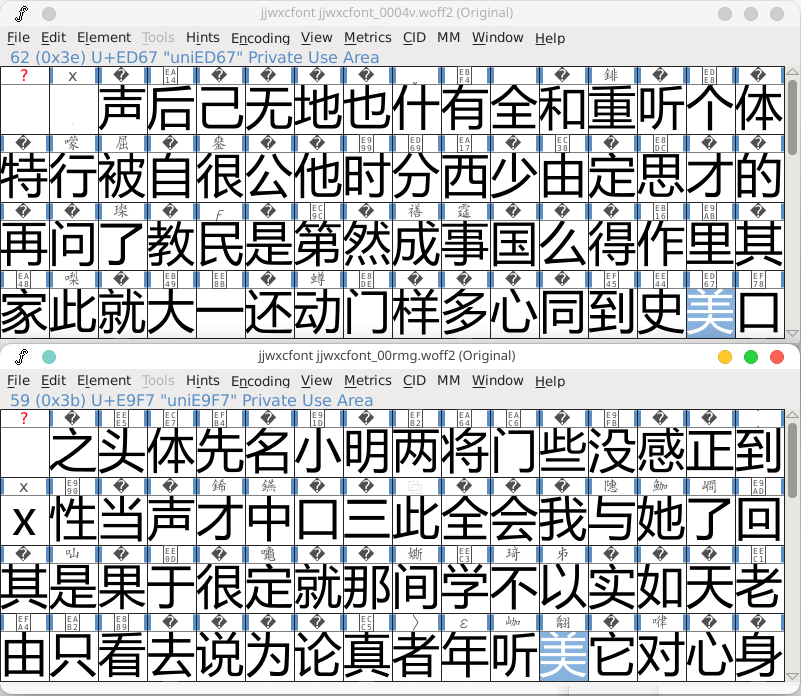
如同许多网站一样,晋江的自定义字体并不是只有一套,而是有很多套。
但比较不同自定义字体,可以很容易发现:虽然每种字体的字符排序不同,但对于同一个汉字,不同之字体之间好像都长得一样呀!
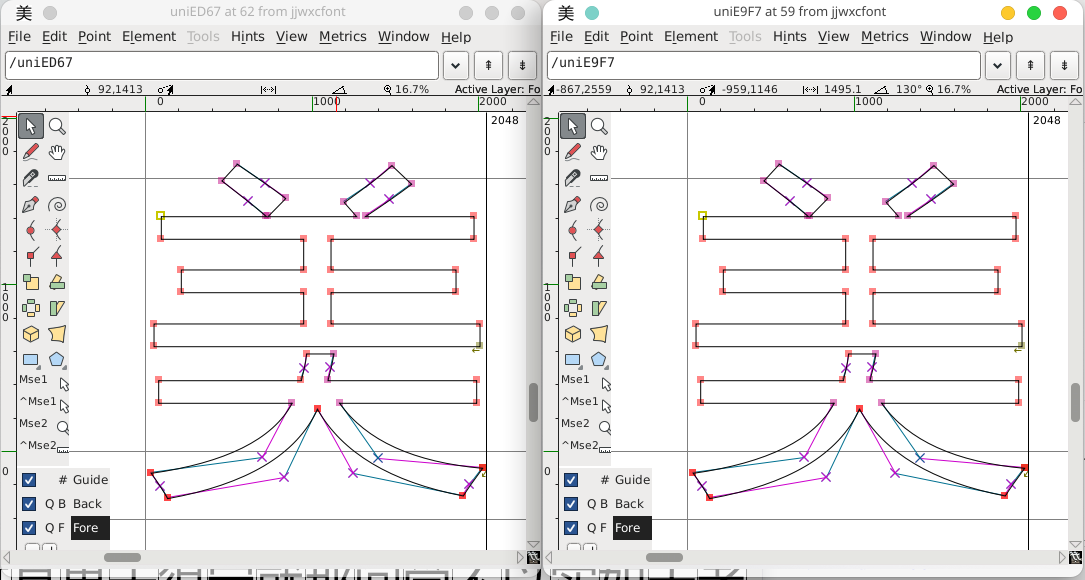
打开编辑界面,果然是一样的(注意左上角被选择的点的坐标值)。
因此,可以根据这一点,通过直接比较字体快速识别。
def getCoord(char: str, ttf: ttFont.TTFont) -> list[tuple[int, int]]:
"""
获取特定字体,指定字符的 coord
"""
cmap = ttf.getBestCmap()
glyf_name = cmap[ord(char)]
coord = ttf['glyf'][glyf_name].coordinates
coord_list = list(coord)
return coord_list
def getCoorTable(fontTable: dict[str, str], fontttf: ttFont.TTFont) -> dict[str, list[tuple[int, int]]]:
"""
获取指定字体的 coordTable
"""
fontTableR = dict(zip(fontTable.values(), fontTable.keys()))
coordTable = dict(
zip(
fontTableR.keys(),
map(lambda x: getCoord(x, fontttf), fontTableR.values())
)
)
return coordTable
本法要求一套已经识别完毕并且没有错识的字体作为标本,这里使用第一部分识别产生的 table。
print(table)
coorTable = getCoorTable(table, ttf)
print(coorTable['见'])
接下来,便可以直接通过比较字体而进行识别了。
加载并识别另外一个字体 jjwxcfont_00rmg.woff2
def is_glpyh_similar(a: list[tuple[int, int]], b: list[tuple[int, int]], fuzz: int):
"""
比较两字符 coor 是否相似。
"""
if len(a) != len(b):
return False
found = True
for i in range(len(a)):
if abs(a[i][0] - b[i][0]) > fuzz or abs(a[i][1] - b[i][1]) > fuzz:
found = False
break
return found
def quickMatch(jj: str, ttf: ttFont.TTFont, stdCoorTable: dict[str, list[list[int, int]]]) -> str:
"""
通过直接比较字体快速匹配
"""
FUZZ = 20
jjCoord = getCoord(jj, ttf)
for stdKey in stdCoorTable:
stdCoord = stdCoorTable[stdKey]
if is_glpyh_similar(jjCoord, stdCoord, FUZZ):
return stdKey
#加载字体 jjwxcfont_00rmg
font2path = os.path.join(FontsDir, 'jjwxcfont_00rmg.woff2')
with tempfile.TemporaryFile() as tmp:
woff2.decompress(font2path, tmp)
tmp.seek(0)
ttf2 = ttFont.TTFont(tmp)
#比较字体 jjwxcfont_00rmg
results = {}
jj2Keys = listTTF(ttf2)
for jj2 in jj2Keys:
mchar = quickMatch(jj2, ttf2, coorTable)
results[jj2] = mchar
print(results)